Redis Is Fast, but You Need to Know More
Redis is a very good distributed caching service you can use to improve your services’ performance. Most important is FAST! Redis is really fast in terms of caching. At my work, running a data centric web services, we use Redis heavily to make sure our users can see and visualize data right away.
Our services start with a single Redis instance in Azure. We choose the most expensive plan to achieve the highest network bandwidth and throughput — it’s a 53GB single instance redis cache. As we use this Redis cache more and more widely, we start seeing a simple READ action takes about 200ms to retrieve a JSON of 100KB. Adding a few hundred milliseconds to a AJAX calls on a page may not to be a big deal, but if there are a lot of data calls it starts impacting user experience. In addition, our services could get into a burst situation to request cache that slows down the performance even more.
While I’m thinking of how to improve the performance, Redis Cluster comes to my mind. Comparing to single instance, the promise of cluster protocol is to significantly improve throughput by sharding the keys into multiple nodes in the cluster.
For example, if your key is a string like http://my-api.com/key1, the whole key could be sharded to one of node. But if your key is like {shard1}http://my-api.com/key1, only shard1 will be used to shard. Therefore you could have more granular control over where you want to cache your data to avoid some other heave cache items.
Azure Redis Cache provides you managed cluster sku, so you do not need to worry about how to config and setup one. The more interesting thing I want to uncover here is a comparison between single instance cache and cluster cache.
Two environments were setup: 1) Premium 53GB with highest network bandwidth (the best we can select); 2) Premium entry level 6GB moderate network bandwidth with two nodes in cluster. Redis benchmark tool is used to perform the benchmark test. The two command we care about is SET and GET. You can execute a simple command to issue thousands of request to your Redis cache. In this experiment, we issue 1000 SET request in a concurrency of 25 parallel request and another 1000 GET requests to retrieve the previous SET with the same concurrency.
1 | redis-benchmark -h my-exp-redis-cache.redis.cache.windows.net -a <password> -c 25 -n 1000 -t get,set -d 100000 -q |
For details of the command options, you can take a look at this article.
Item size is big factor for your cache performance, so I ran the comparison among 100kb, 200kb, 500kb, 1mb, 2mb. The results are showing below.
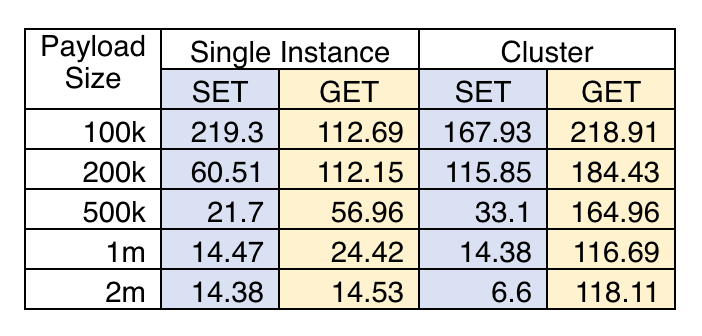
The unit of the numbers is requests/second. To visualize the results below.
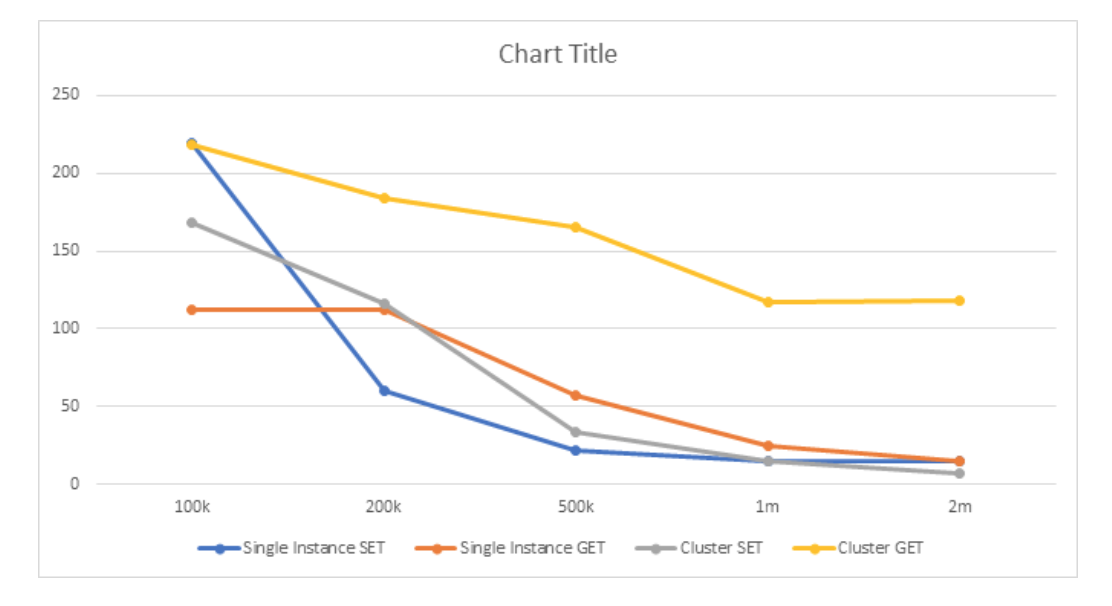
An obvious trend is that throughput decreases as the item size gets bigger. So smaller items are better in terms of performance on either GET or SET command.
The exciting part of this benchmark is the GET throughput of the Redis cluster. The requests/second decreases less than 50% when the item size is 20x bigger. So if you have bigger item size, Redis cluster might be a good choice.
The other side of the story is related to the actual cache item size. We use application insights to log every cache actions. The biggest item is 4.8mb but only one. The top 1000 items are between 1mb and 1.8mb. However, the 99th percentile is only 19kb. So you may argue to continue using the single instance of redis cache. Unfortunately, the big items are normally accessed from our very important and heavily used pages. If you improve these 1% cache retrieves by 7x faster, you would get a much better user experience at your websites.
Cost-wise, running a cluster mode could be cheaper to achieve the same or better performance. The 2-node 6GB redis cluster is only a quarter of the cost of a highest 53GB single instance cache. Or with the same price, you can have an 8-node cluster cache.
You may even want to optimize the sharding strategy of Redis cluster by providing your own shard key. For example, you can separate some heavily used cache item into a few nodes while evenly shard other keys to achieve better performance overall.